As AI moves from experimental chat interfaces to production-grade agents, the need for a foundational memory layer to transform these AI-powered tasks into stateful models is apparent.
The absence of a robust memory layer causes agents to lose vital statefulness, leading to:
-
Inability to maintain long-term recall. Without persistent memory to track context across sessions, an agent might recognize specific user preferences in January but fail to apply that data months later, requiring the user to repeat the entire briefing.
-
Vulnerability in multi-stage workflows. Lacking durable execution, there is no “save point” for recovery; consequently, a simple network interruption forces complex agentic processes, such as gathering diagnostic data via multiple tool calls, to restart entirely rather than resume from the point of failure.
-
Disconnect from business-specific realities. If an agent cannot access private internal records or real-time operational data, it relies on general training data and guesswork, often confidently fabricating generic policies or specifications that are factually inaccurate for your organization.
DigitalOcean is constantly evolving to meet this challenge, and we’ve entered the era of the inference cloud: A full-stack cloud platform purpose-built to run AI in production. With Gradient™AI Platform providing the specialized compute for AI applications, DigitalOcean Managed Databases serves as the foundational memory layer. Offerings from PostgreSQL, MongoDB, and Valkey function as the system of record for today’s stateful AI applications, particularly so when they’re connected to the DigitalOcean Agentic Inference Cloud.
What is the inference cloud?
The need for an inference cloud stems from a fundamental shift in how AI is being built, deployed, and used in 2026. For years, the industry’s focus was on training or the capital-intensive process of building a model. But now developers are shifting to running that pre-trained model in a live product. Training and production are two entirely different tasks that require distinct system architectures and environments.
Training vs. inference: the production gap
Training is about raw power and high GPU utilization. Inference, however, is where your AI meets your users. This creates a production gap in infrastructure requirements. While for training, you mainly need high throughput and increased computing power, these are just starting features for inference workloads. To deliver a seamless user experience, inference requires:
-
Low, predictable latency: Have a setup where users won’t wait seconds as your application buffers.
-
Elastic scaling: Your infrastructure must handle fluctuating, real-world traffic without breaking.
-
High sustained throughput: The network needs to reliably process millions of requests under heavy load.
-
Cost predictability: Select a provider with transparent pricing so that as your user base grows, your margins don’t disappear.
To meet these requirements, developers must have the right infrastructure and management tools. For teams that don’t want to manually configure their tech stack, using an inference cloud provider is a straightforward option to support reliability, scalability, and cost predictability without requiring developers to spend unnecessary time on software setup and integration. Using managed Kubernetes, databases, and networking assists teams to readily support inference workloads in a matter of hours and to have a fully integrated, future-proof platform.
Architecting the memory layer: a mapping matrix
To understand where Managed Databases fit within the overall inference cloud, we need to examine the data requirements of an inference-driven application. Some are genuinely new patterns that emerged with large-language models (LLMs) and agent architectures. Others are established techniques applied to a new workload class. DigitalOcean Managed Databases support all the following use cases:
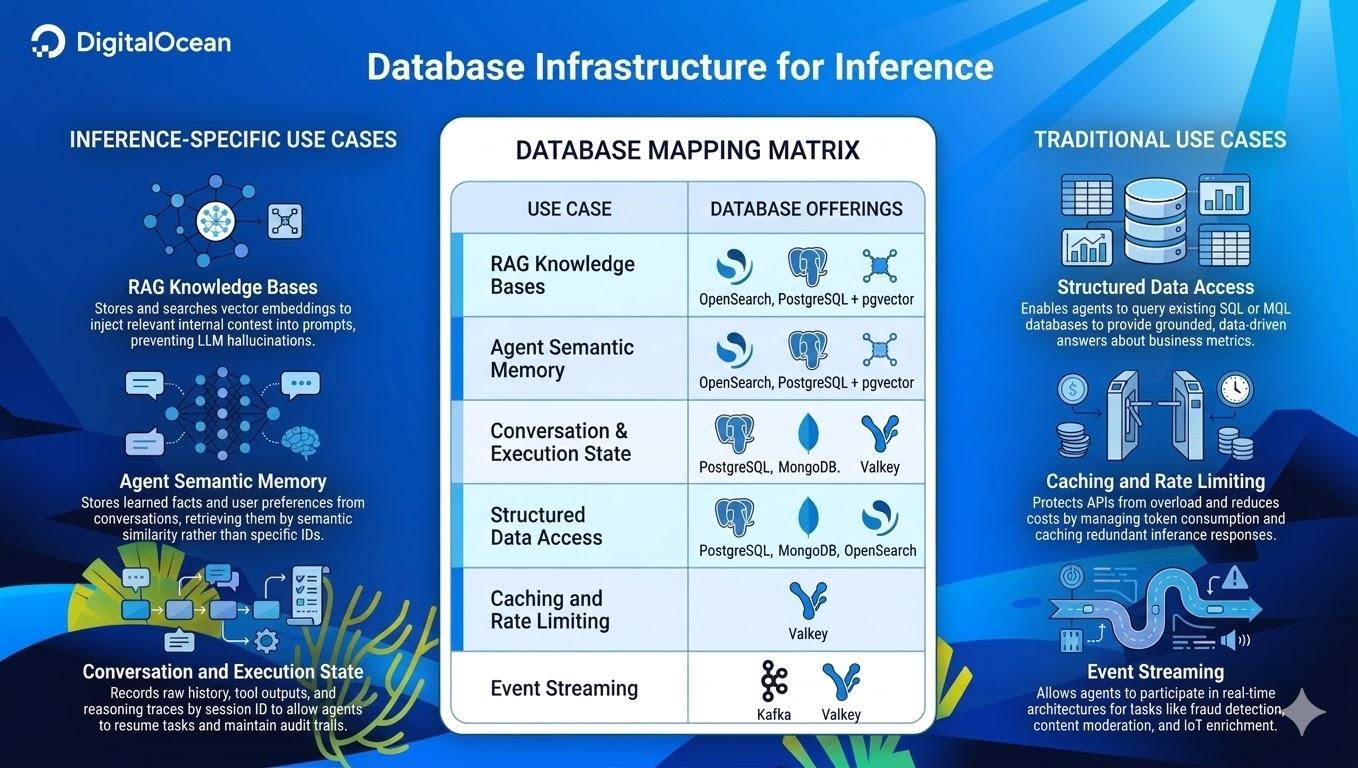
1. RAG knowledge bases (context)
RAG is how you ground LLM responses in your actual data. The system converts a user’s question into a vector embedding, searches your knowledge base for semantically similar content, and collects the best matches into the prompt, replacing hallucination with real answers.
-
Managed OpenSearch is the recommended default for new RAG workloads, combining keyword matching (BM25) with semantic similarity in a single hybrid query. This is the same engine that powers Knowledge Bases on the Gradient AI Platform.
-
Managed PostgreSQL and
pgvectoris ideal for PostgreSQL deployments where you want vectors alongside your relational data. pgvectorscale on PostgreSQL 16+ handles most production RAG workloads well.
2. Agent semantic memory (recall)
Retrieval-Augmented Generation (“RAG”) searches your documents to find relevant responses. Semantic memory searches what the agent has learned: extracted facts, user preferences, and knowledge accumulated across conversations, retrieved by similarity to the current context. When a user says “I’m hungry,” the agent recalls “user is vegetarian” and “user likes Thai food” from its own memory, not your connected knowledge base.
-
Managed OpenSearch provides vector search via its k-NN plugin, with purpose-built agentic memory APIs added in version 3.3.
-
Managed PostgreSQL + pgvector keeps semantic memories alongside your relational data in the same database.
3. Conversation and execution state (durability)
This is the agent’s record log for every action it does (conversation history, tool call inputs/outputs, reasoning traces, and checkpoints), accessed by direct lookup (session ID, thread ID), not similarity search. The core capability this layer provides is durable execution: Agent workflows that can be paused, resumed, rewound, and recovered from failure at any step. This is because the data’s state is persisted to the database at each stage rather than held in memory.
-
Managed PostgreSQL is ideal when your state schema is stable, and you want relational guarantees.
-
Managed MongoDB excels when your agent’s capabilities (and state schema) evolve rapidly. Its flexible document model naturally accommodates complex, nested JSON data such as reasoning traces (the step-by-step logs of an agent’s internal logic) and varied tool outputs without requiring a rigid schema.
-
Managed Valkey handles short-lived session state with TTL expiration, but is not a substitute for durable execution.
4. Structured data access (business data)
When agents can query your operational data, translating natural language into SQL, MQL, or OpenSearch queries, they stop hallucinating less about “your sales last quarter” and start delivering more real answers. This doesn’t require new infrastructure. With DigitalOcean, your existing Managed PostgreSQL, MongoDB, or OpenSearch instances are already agent-ready.
5. Caching and rate limiting (performance)
Inference calls are expensive and latency-sensitive. Caching identical responses helps avoid redundant GPU cycles, and rate limiting helps prevent runaway costs. These familiar patterns take on new urgency when a single LLM call costs significantly more than a traditional API request.
- Managed Valkey (Our open-source Redis-compatible service) provides exact-match response caching and token-based rate limiting (tokens consumed per day per user, not just requests per minute). It is ideal for high-volume, repetitive tasks such as FAQ bots and customer support.
6. Event streaming (Reactivity)
Event streaming enables agents to move beyond request-response to continuous processing for use cases such as real-time content moderation, automated triage, and fraud detection.
-
Managed Kafka provides durable, replayable streaming at scale (1,000+ events/second with full audit trails).
-
Managed Valkey offers lighter-weight streaming via Redis Streams and pub/sub when simplicity matters more than durability.
What DigitalOcean’s Agentic Inference Cloud configuration looks like
So how does everything tie together? Below is what a production inference environment looks like on DigitalOcean’s Agentic Inference Cloud.
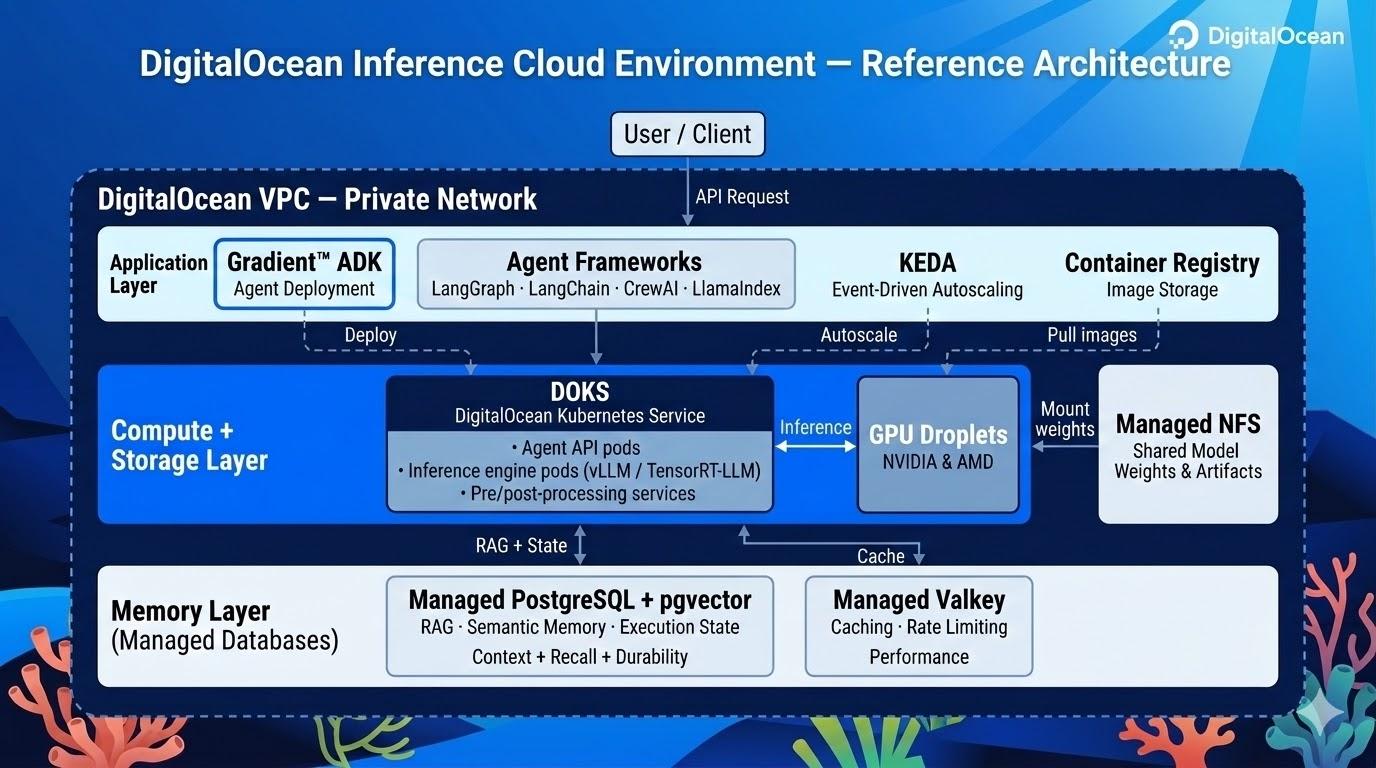
The application layer: orchestration and frameworks
The application layer is where your agent logic lives. The open-source ecosystem for AI agents and inference is rich and framework agnostic, so it can integrate directly with DigitalOcean services.
Agent deployment:
- The DigitalOcean Gradient AI Platform Agent Development Kit (ADK) is a Python SDK and CLI that takes your agent code and deploys it as a hosted, production-ready service with built-in logging and execution traces. The ADK is framework-agnostic and you can keep your abstractions whether you build with LangGraph, LangChain, CrewAI, PydanticAI, or fully custom orchestration. The key advantage is closing the gap between prototype and production without re-architecting your agent, so you focus on behavior, the platform handles execution, observability, and infrastructure.
Agent orchestration and state management:
-
LangGraph and LangChain are frameworks for building agent workflows. Both integrate with Managed PostgreSQL and MongoDB for durable execution (checkpointing, fault recovery, and semantic memory search) out of the box.
-
CrewAI and AutoGen offer alternative orchestration patterns for multi-agent systems with built-in memory and state management.
RAG and knowledge ingestion:
-
LlamaIndex is optimized for document indexing and retrieval pipelines that populate your OpenSearch or pgvector knowledge base.
-
LangChain provides a general-purpose orchestration layer with the largest ecosystem of integrations, including SQL agents and text-to-MQL agents for structured data access.
-
Haystack is popular for production RAG pipelines, particularly in regulated industries.
Agent memory:
- Mem0 provides a lightweight, production-focused memory layer. Letta (formerly MemGPT) supports self-editing memory. Zep builds temporal knowledge graphs. LangMem is LangChain’s native memory module. All of these memory modules treat Managed Databases as their underlying vector and state stores.
Infrastructure and scaling:
-
Kubernetes Event-Driven Autoscaling (KEDA) on DOKS scales inference pods based on queue depth, request rate, or custom metrics from your Kafka streams.
-
DigitalOcean Container Registry stores and versions your application images with private access from your DOKS cluster.
The compute and storage layer: DOKS, GPU Droplets, and Managed NFS
DigitalOcean’s Kubernetes Service (DOKS) is at the center of the architecture, running your inference services as containerized workloads. DOKS provides the orchestration layer that handles scaling, health checks, and rolling deployments, so you can focus on your application logic.
DigitalOcean GPU-based Droplets® (NVIDIA and AMD) provide dedicated compute for model serving. Pair them with inference engines like vLLM or TensorRT-LLM running on DOKS, and you get full control over model configuration, batching, and optimization. DOKS acts as the application runtime. Your agent logic, API gateways, pre/post-processing services, and orchestration layers all run as Kubernetes workloads with private network access to both the compute and the memory layer.
Running your own models requires efficiently getting large model weights (often tens of gigabytes) onto your inference nodes. Our Managed Network File Storage (NFS) provides a shared, POSIX-compatible file system that multiple inference pods can mount simultaneously. You can download a model once and serve it from multiple pods without redundant copies. As you scale your inference fleet, new pods mount the same shared volume and begin serving immediately without waiting for a separate model download.
The memory layer: Managed Databases
Your DOKS workloads connect to Managed Databases over DigitalOcean’s Virtual Private Cloud network, keeping all traffic off the public internet with low, predictable latency. For most teams, the lowest-barrier starting point is two services:
-
Managed PostgreSQL + pgvector serves as both your RAG knowledge base and your execution state store in a single database. Store vector embeddings for semantic search alongside conversation history, tool outputs, and agent reasoning traces, all with durable execution support out of the box. PostgreSQL is the Swiss Army knife here: one connection string covers context, recall, and durability.
-
Managed Valkey adds the performance layer: exact-match response caching and token-based rate limiting to protect your inference APIs from redundant calls and runaway costs.
As your workloads mature, you can scale to purpose-built databases (OpenSearch for hybrid RAG search, MongoDB for rapidly evolving agent schemas, and Kafka for event streaming), but PostgreSQL and Valkey cover the core needs on day one. Each is a fully-managed service with automated backups, high availability, failover, and connection pooling. Putting it all together
Here’s how the pieces connect in a representative agent architecture:
-
A user sends a message to your agent API, running on DOKS.
-
The agent checks Managed Valkey for a cached response. On a miss, it retrieves the user’s conversation history and semantic memories from Managed PostgreSQL.
-
It builds a prompt with RAG context pulled from PostgreSQL + pgvector, grounding the LLM response in your actual data.
-
The prompt is sent to the model, served via vLLM or TensorRT-LLM on GPU Droplets managed through DOKS.
-
The model response is returned, the agent logs the full interaction (including tool calls and reasoning traces) back to PostgreSQL, caches the response in Valkey, and replies to the user.
Every component in this flow is a managed DigitalOcean service. No self-managed databases, no hand-rolled caching infrastructure, no DIY event buses. You build the agent logic. DigitalOcean runs the platform.
Use DigitalOcean for your production-ready inference workloads
Building an AI startup or scaling an enterprise AI feature requires moving fast while keeping complexity and costs down. DigitalOcean is uniquely positioned to handle your inference workloads while keeping these parameters in mind.
Enterprise workloads, zero friction
DigitalOcean Managed Databases provide production-grade architecture with features such as High Availability (HA), automated failover, and VPC peering for secure internal networking, and automated backups–all without the complex pricing of hyperscalers. With DigitalOcean, there are no complex components to manage, rather just a connection string that works.
The power of integration
Pairing DOKS with Managed Databases creates a cohesive infrastructure. Your inference services run in containers, scale horizontally, and maintain a low-latency private connection to the memory layer.
Predictable scaling for AI-native enterprises
Whether you are a digital-native enterprise or a scaling startup, your data needs will grow. We offer a progressive path:
-
Start small: Launch a single-node cluster for $15/month to test your RAG prototype.
-
Scale high: Move to high-memory, multi-node configurations as your agentic workflows hit millions of users—all with clear, transparent pricing.
The shift from AI as a feature to AI as an operating model requires a fundamental rethink of the data layer. By treating DigitalOcean Managed Databases as the memory foundation of your inference cloud, we enable developers to focus on building the next generation of intelligent applications while we handle the data persistence, coordination, and scale.