Vidhya Arvind, Rajasekhar Ummadisetty, Joey Lynch, Vinay Chella
Introduction
At Netflix our ability to deliver seamless, high-quality, streaming experiences to millions of users hinges on robust, global backend infrastructure. Central to this infrastructure is our use of multiple online distributed databases such as Apache Cassandra, a NoSQL database known for its high availability and scalability. Cassandra serves as the backbone for a diverse array of use cases within Netflix, ranging from user sign-ups and storing viewing histories to supporting real-time analytics and live streaming.
Over time as new key-value databases were introduced and service owners launched new use cases, we encountered numerous challenges with datastore misuse. Firstly, developers struggled to reason about consistency, durability and performance in this complex global deployment across multiple stores. Second, developers had to constantly re-learn new data modeling practices and common yet critical data access patterns. These include challenges with tail latency and idempotency, managing “wide” partitions with many rows, handling single large “fat” columns, and slow response pagination. Additionally, the tight coupling with multiple native database APIs — APIs that continually evolve and sometimes introduce backward-incompatible changes — resulted in org-wide engineering efforts to maintain and optimize our microservice’s data access.
To overcome these challenges, we developed a holistic approach that builds upon our Data Gateway Platform. This approach led to the creation of several foundational abstraction services, the most mature of which is our Key-Value (KV) Data Abstraction Layer (DAL). This abstraction simplifies data access, enhances the reliability of our infrastructure, and enables us to support the broad spectrum of use cases that Netflix demands with minimal developer effort.
In this post, we dive deep into how Netflix’s KV abstraction works, the architectural principles guiding its design, the challenges we faced in scaling diverse use cases, and the technical innovations that have allowed us to achieve the performance and reliability required by Netflix’s global operations.
The Key-Value Service
The KV data abstraction service was introduced to solve the persistent challenges we faced with data access patterns in our distributed databases. Our goal was to build a versatile and efficient data storage solution that could handle a wide variety of use cases, ranging from the simplest hashmaps to more complex data structures, all while ensuring high availability, tunable consistency, and low latency.
Data Model
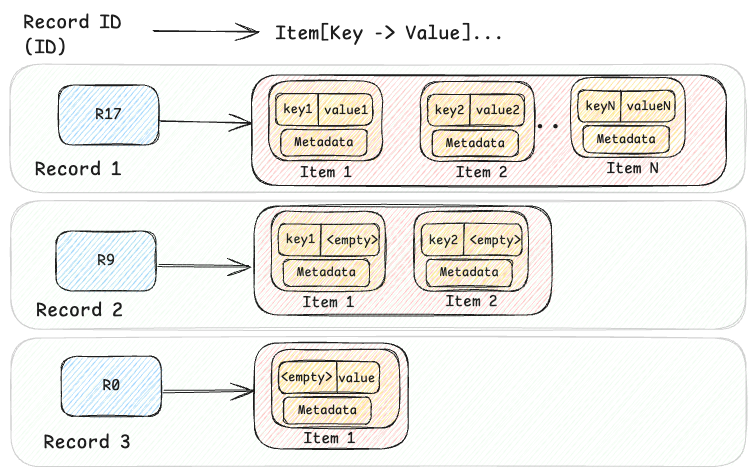
At its core, the KV abstraction is built around a two-level map architecture. The first level is a hashed string ID (the primary key), and the second level is a sorted map of a key-value pair of bytes. This model supports both simple and complex data models, balancing flexibility and efficiency.
HashMap<String, SortedMap<Bytes, Bytes>>
For complex data models such as structured Records or time-ordered Events, this two-level approach handles hierarchical structures effectively, allowing related data to be retrieved together. For simpler use cases, it also represents flat key-value Maps (e.g. id → {"" → value}) or named Sets (e.g.id → {key → ""}). This adaptability allows the KV abstraction to be used in hundreds of diverse use cases, making it a versatile solution for managing both simple and complex data models in large-scale infrastructures like Netflix.
The KV data can be visualized at a high level, as shown in the diagram below, where three records are shown.
message Item (
Bytes key,
Bytes value,
Metadata metadata,
Integer chunk
)
Database Agnostic Abstraction
The KV abstraction is designed to hide the implementation details of the underlying database, offering a consistent interface to application developers regardless of the optimal storage system for that use case. While Cassandra is one example, the abstraction works with multiple data stores like EVCache, DynamoDB, RocksDB, etc…
For example, when implemented with Cassandra, the abstraction leverages Cassandra’s partitioning and clustering capabilities. The record ID acts as the partition key, and the item key as the clustering column:

The corresponding Data Definition Language (DDL) for this structure in Cassandra is:
CREATE TABLE IF NOT EXISTS <ns>.<table> (
id text,
key blob,
value blob,
value_metadata blob,
PRIMARY KEY (id, key))
WITH CLUSTERING ORDER BY (key <ASC|DESC>)
Namespace: Logical and Physical Configuration
A namespace defines where and how data is stored, providing logical and physical separation while abstracting the underlying storage systems. It also serves as central configuration of access patterns such as consistency or latency targets. Each namespace may use different backends: Cassandra, EVCache, or combinations of multiple. This flexibility allows our Data Platform to route different use cases to the most suitable storage system based on performance, durability, and consistency needs. Developers just provide their data problem rather than a database solution!
In this example configuration, the ngsegment namespace is backed by both a Cassandra cluster and an EVCache caching layer, allowing for highly durable persistent storage and lower-latency point reads.
"persistence_configuration":[
{
"id":"PRIMARY_STORAGE",
"physical_storage": {
"type":"CASSANDRA",
"cluster":"cassandra_kv_ngsegment",
"dataset":"ngsegment",
"table":"ngsegment",
"regions": ["us-east-1"],
"config": {
"consistency_scope": "LOCAL",
"consistency_target": "READ_YOUR_WRITES"
}
}
},
{
"id":"CACHE",
"physical_storage": {
"type":"CACHE",
"cluster":"evcache_kv_ngsegment"
},
"config": {
"default_cache_ttl": 180s
}
}
]
Key APIs of the KV Abstraction
To support diverse use-cases, the KV abstraction provides four basic CRUD APIs:
PutItems — Write one or more Items to a Record
The PutItems API is an upsert operation, it can insert new data or update existing data in the two-level map structure.
message PutItemRequest (
IdempotencyToken idempotency_token,
string namespace,
string id,
List<Item> items
)
As you can see, the request includes the namespace, Record ID, one or more items, and an idempotency token to ensure retries of the same write are safe. Chunked data can be written by staging chunks and then committing them with appropriate metadata (e.g. number of chunks).
GetItems — Read one or more Items from a Record
The GetItemsAPI provides a structured and adaptive way to fetch data using ID, predicates, and selection mechanisms. This approach balances the need to retrieve large volumes of data while meeting stringent Service Level Objectives (SLOs) for performance and reliability.
message GetItemsRequest (
String namespace,
String id,
Predicate predicate,
Selection selection,
Map<String, Struct> signals
)
The GetItemsRequest includes several key parameters:
- Namespace: Specifies the logical dataset or table
- Id: Identifies the entry in the top-level HashMap
- Predicate: Filters the matching items and can retrieve all items (match_all), specific items (match_keys), or a range (match_range)
- Selection: Narrows returned responses for example page_size_bytes for pagination, item_limit for limiting the total number of items across pages and include/exclude to include or exclude large values from responses
- Signals: Provides in-band signaling to indicate client capabilities, such as supporting client compression or chunking.
The GetItemResponse message contains the matching data:
message GetItemResponse (
List<Item> items,
Optional<String> next_page_token
)
- Items: A list of retrieved items based on the Predicate and Selection defined in the request.
- Next Page Token: An optional token indicating the position for subsequent reads if needed, essential for handling large data sets across multiple requests. Pagination is a critical component for efficiently managing data retrieval, especially when dealing with large datasets that could exceed typical response size limits.
DeleteItems — Delete one or more Items from a Record
The DeleteItems API provides flexible options for removing data, including record-level, item-level, and range deletes — all while supporting idempotency.
message DeleteItemsRequest (
IdempotencyToken idempotency_token,
String namespace,
String id,
Predicate predicate
)
Just like in the GetItems API, the Predicate allows one or more Items to be addressed at once:
- Record-Level Deletes (match_all): Removes the entire record in constant latency regardless of the number of items in the record.
- Item-Range Deletes (match_range): This deletes a range of items within a Record. Useful for keeping “n-newest” or prefix path deletion.
- Item-Level Deletes (match_keys): Deletes one or more individual items.
Some storage engines (any store which defers true deletion) such as Cassandra struggle with high volumes of deletes due to tombstone and compaction overhead. Key-Value optimizes both record and range deletes to generate a single tombstone for the operation — you can learn more about tombstones in About Deletes and Tombstones.
Item-level deletes create many tombstones but KV hides that storage engine complexity via TTL-based deletes with jitter. Instead of immediate deletion, item metadata is updated as expired with randomly jittered TTL applied to stagger deletions. This technique maintains read pagination protections. While this doesn’t completely solve the problem it reduces load spikes and helps maintain consistent performance while compaction catches up. These strategies help maintain system performance, reduce read overhead, and meet SLOs by minimizing the impact of deletes.
Complex Mutate and Scan APIs
Beyond simple CRUD on single Records, KV also supports complex multi-item and multi-record mutations and scans via MutateItems and ScanItems APIs. PutItems also supports atomic writes of large blob data within a single Item via a chunked protocol. These complex APIs require careful consideration to ensure predictable linear low-latency and we will share details on their implementation in a future post.
Design Philosophies for reliable and predictable performance
Idempotency to fight tail latencies
To ensure data integrity the PutItems and DeleteItems APIs use idempotency tokens, which uniquely identify each mutative operation and guarantee that operations are logically executed in order, even when hedged or retried for latency reasons. This is especially crucial in last-write-wins databases like Cassandra, where ensuring the correct order and de-duplication of requests is vital.
In the Key-Value abstraction, idempotency tokens contain a generation timestamp and random nonce token. Either or both may be required by backing storage engines to de-duplicate mutations.
message IdempotencyToken (
Timestamp generation_time,
String token
)
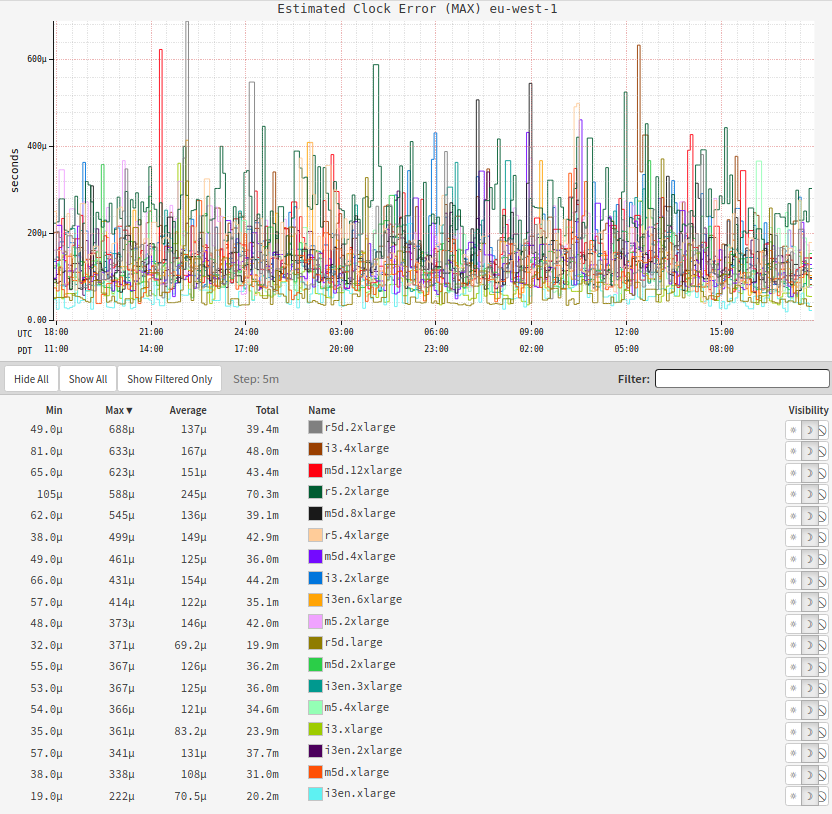
At Netflix, client-generated monotonic tokens are preferred due to their reliability, especially in environments where network delays could impact server-side token generation. This combines a client provided monotonic generation_time timestamp with a 128 bit random UUID token. Although clock-based token generation can suffer from clock skew, our tests on EC2 Nitro instances show drift is minimal (under 1 millisecond). In some cases that require stronger ordering, regionally unique tokens can be generated using tools like Zookeeper, or globally unique tokens such as a transaction IDs can be used.
The following graphs illustrate the observed clock skew on our Cassandra fleet, suggesting the safety of this technique on modern cloud VMs with direct access to high-quality clocks. To further maintain safety, KV servers reject writes bearing tokens with large drift both preventing silent write discard (write has timestamp far in past) and immutable doomstones (write has a timestamp far in future) in storage engines vulnerable to those.
Handling Large Data through Chunking
Key-Value is also designed to efficiently handle large blobs, a common challenge for traditional key-value stores. Databases often face limitations on the amount of data that can be stored per key or partition. To address these constraints, KV uses transparent chunking to manage large data efficiently.
For items smaller than 1 MiB, data is stored directly in the main backing storage (e.g. Cassandra), ensuring fast and efficient access. However, for larger items, only the id, key, and metadata are stored in the primary storage, while the actual data is split into smaller chunks and stored separately in chunk storage. This chunk storage can also be Cassandra but with a different partitioning scheme optimized for handling large values. The idempotency token ties all these writes together into one atomic operation.
By splitting large items into chunks, we ensure that latency scales linearly with the size of the data, making the system both predictable and efficient. A future blog post will describe the chunking architecture in more detail, including its intricacies and optimization strategies.
Client-Side Compression
The KV abstraction leverages client-side payload compression to optimize performance, especially for large data transfers. While many databases offer server-side compression, handling compression on the client side reduces expensive server CPU usage, network bandwidth, and disk I/O. In one of our deployments, which helps power Netflix’s search, enabling client-side compression reduced payload sizes by 75%, significantly improving cost efficiency.
Smarter Pagination
We chose payload size in bytes as the limit per response page rather than the number of items because it allows us to provide predictable operation SLOs. For instance, we can provide a single-digit millisecond SLO on a 2 MiB page read. Conversely, using the number of items per page as the limit would result in unpredictable latencies due to significant variations in item size. A request for 10 items per page could result in vastly different latencies if each item was 1 KiB versus 1 MiB.
Using bytes as a limit poses challenges as few backing stores support byte-based pagination; most data stores use the number of results e.g. DynamoDB and Cassandra limit by number of items or rows. To address this, we use a static limit for the initial queries to the backing store, query with this limit, and process the results. If more data is needed to meet the byte limit, additional queries are executed until the limit is met, the excess result is discarded and a page token is generated.
This static limit can lead to inefficiencies, one large item in the result may cause us to discard many results, while small items may require multiple iterations to fill a page, resulting in read amplification. To mitigate these issues, we implemented adaptive pagination which dynamically tunes the limits based on observed data.
Adaptive Pagination
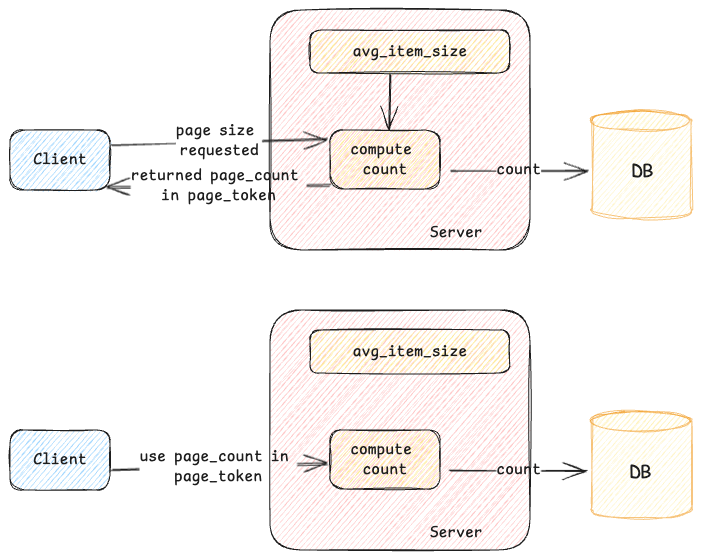
When an initial request is made, a query is executed in the storage engine, and the results are retrieved. As the consumer processes these results, the system tracks the number of items consumed and the total size used. This data helps calculate an approximate item size, which is stored in the page token. For subsequent page requests, this stored information allows the server to apply the appropriate limits to the underlying storage, reducing unnecessary work and minimizing read amplification.
While this method is effective for follow-up page requests, what happens with the initial request? In addition to storing item size information in the page token, the server also estimates the average item size for a given namespace and caches it locally. This cached estimate helps the server set a more optimal limit on the backing store for the initial request, improving efficiency. The server continuously adjusts this limit based on recent query patterns or other factors to keep it accurate. For subsequent pages, the server uses both the cached data and the information in the page token to fine-tune the limits.
In addition to adaptive pagination, a mechanism is in place to send a response early if the server detects that processing the request is at risk of exceeding the request’s latency SLO.
For example, let us assume a client submits a GetItems request with a per-page limit of 2 MiB and a maximum end-to-end latency limit of 500ms. While processing this request, the server retrieves data from the backing store. This particular record has thousands of small items so it would normally take longer than the 500ms SLO to gather the full page of data. If this happens, the client would receive an SLO violation error, causing the request to fail even though there is nothing exceptional. To prevent this, the server tracks the elapsed time while fetching data. If it determines that continuing to retrieve more data might breach the SLO, the server will stop processing further results and return a response with a pagination token.
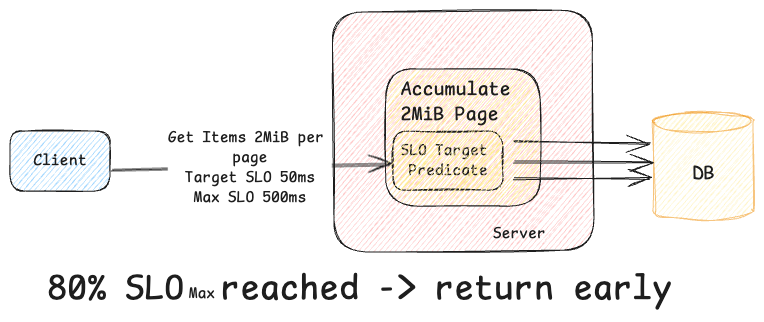
This approach ensures that requests are processed within the SLO, even if the full page size isn’t met, giving clients predictable progress. Furthermore, if the client is a gRPC server with proper deadlines, the client is smart enough not to issue further requests, reducing useless work.
If you want to know more, the How Netflix Ensures Highly-Reliable Online Stateful Systems article talks in further detail about these and many other techniques.
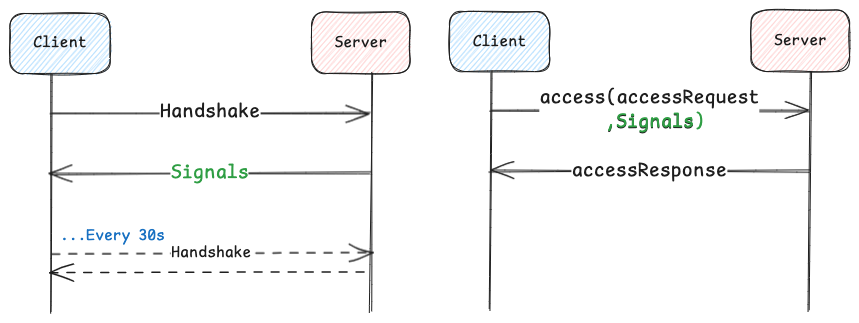
Signaling
KV uses in-band messaging we call signaling that allows the dynamic configuration of the client and enables it to communicate its capabilities to the server. This ensures that configuration settings and tuning parameters can be exchanged seamlessly between the client and server. Without signaling, the client would need static configuration — requiring a redeployment for each change — or, with dynamic configuration, would require coordination with the client team.
For server-side signals, when the client is initialized, it sends a handshake to the server. The server responds back with signals, such as target or max latency SLOs, allowing the client to dynamically adjust timeouts and hedging policies. Handshakes are then made periodically in the background to keep the configuration current. For client-communicated signals, the client, along with each request, communicates its capabilities, such as whether it can handle compression, chunking, and other features.
KV Usage @ Netflix
The KV abstraction powers several key Netflix use cases, including:
- Streaming Metadata: High-throughput, low-latency access to streaming metadata, ensuring personalized content delivery in real-time.
- User Profiles: Efficient storage and retrieval of user preferences and history, enabling seamless, personalized experiences across devices.
- Messaging: Storage and retrieval of push registry for messaging needs, enabling the millions of requests to flow through.
- Real-Time Analytics: This persists large-scale impression and provides insights into user behavior and system performance, moving data from offline to online and vice versa.
Future Enhancements
Looking forward, we plan to enhance the KV abstraction with:
- Lifecycle Management: Fine-grained control over data retention and deletion.
- Summarization: Techniques to improve retrieval efficiency by summarizing records with many items into fewer backing rows.
- New Storage Engines: Integration with more storage systems to support new use cases.
- Dictionary Compression: Further reducing data size while maintaining performance.
Conclusion
The Key-Value service at Netflix is a flexible, cost-effective solution that supports a wide range of data patterns and use cases, from low to high traffic scenarios, including critical Netflix streaming use-cases. The simple yet robust design allows it to handle diverse data models like HashMaps, Sets, Event storage, Lists, and Graphs. It abstracts the complexity of the underlying databases from our developers, which enables our application engineers to focus on solving business problems instead of becoming experts in every storage engine and their distributed consistency models. As Netflix continues to innovate in online datastores, the KV abstraction remains a central component in managing data efficiently and reliably at scale, ensuring a solid foundation for future growth.
Acknowledgments: Special thanks to our stunning colleagues who contributed to Key Value’s success: William Schor, Mengqing Wang, Chandrasekhar Thumuluru, Rajiv Shringi, John Lu, George Cambell, Ammar Khaku, Jordan West, Chris Lohfink, Matt Lehman, and the whole online datastores team (ODS, f.k.a CDE).
Introducing Netflix’s Key-Value Data Abstraction Layer was originally published in Netflix TechBlog on Medium, where people are continuing the conversation by highlighting and responding to this story.